在工作中, 经常的使用memcache, 但是, 对于一直没有对memcache深入探索, 在面试的时候, 问道了memcache, 还有猴哥在QQ上跟我聊这方面的问题, 所以, 决定较为深入的研究一下memcache. 特此做了记录, 方便你我他, 也为了以后跟别人聊起这方便的东西, 有吹的资本.
memcahce简介
主要是用来在内存中存储数据的. 以减轻数据库的压力. 因为是在内存中存储的, 所以读取熟读都是非常快的. 但是也有弊端, 因为是在内存中, 所以如果重启, 数据就会丢失. 这个也是与redis最大的区别之一.
在服务器中, memcached和memcache的概念总是模糊, 我之前也是有些模糊, 所以在这里记录一下.
memcached: 是指在服务器中安装memcache的服务, 安装以后, 启动memcached这个守护进程后, 客户端就可以连接这个进程, 然后存取数据了.
[root@iZ2zef6g8n5jwp5cnlyfacZ ~]# ps aux | grep memcached
503 1018 0.0 0.3 341356 3152 ? Ssl Feb06 4:18 /usr/local/memcached/bin/memcached -d -p 11211 -u memcached -m 124 -c 1024 -P /var/run/memcached/memcached.pid -l 127.0.0.1
root 18264 0.0 0.0 103276 940 pts/1 S+ 16:46 0:00 grep --color memcached
[root@iZ2zef6g8n5jwp5cnlyfacZ ~]#
memcache: 这个是php的缓存扩展, 已经存在php环境了, 则可以通过phpize来安装这个扩展.
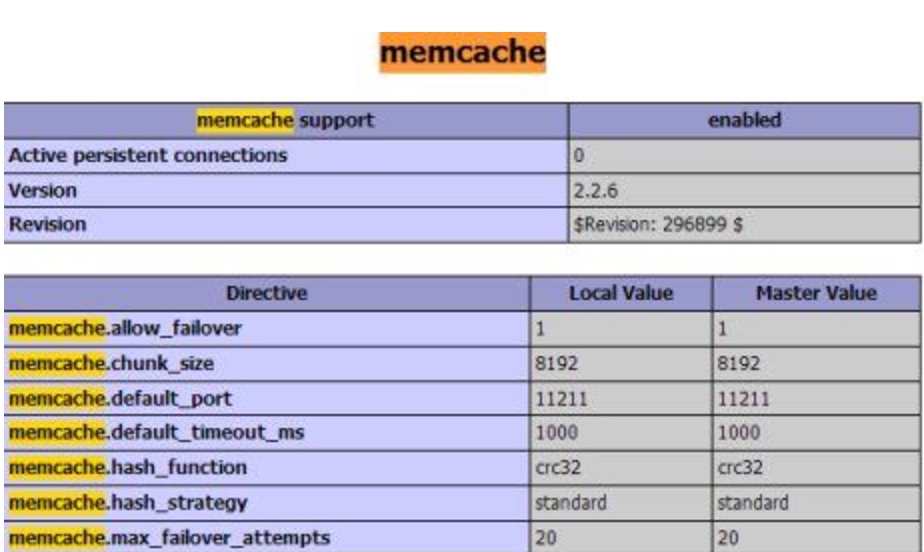
安装及使用
安装网上教程一大堆. 这里直接略过. 说说安装后的东西.
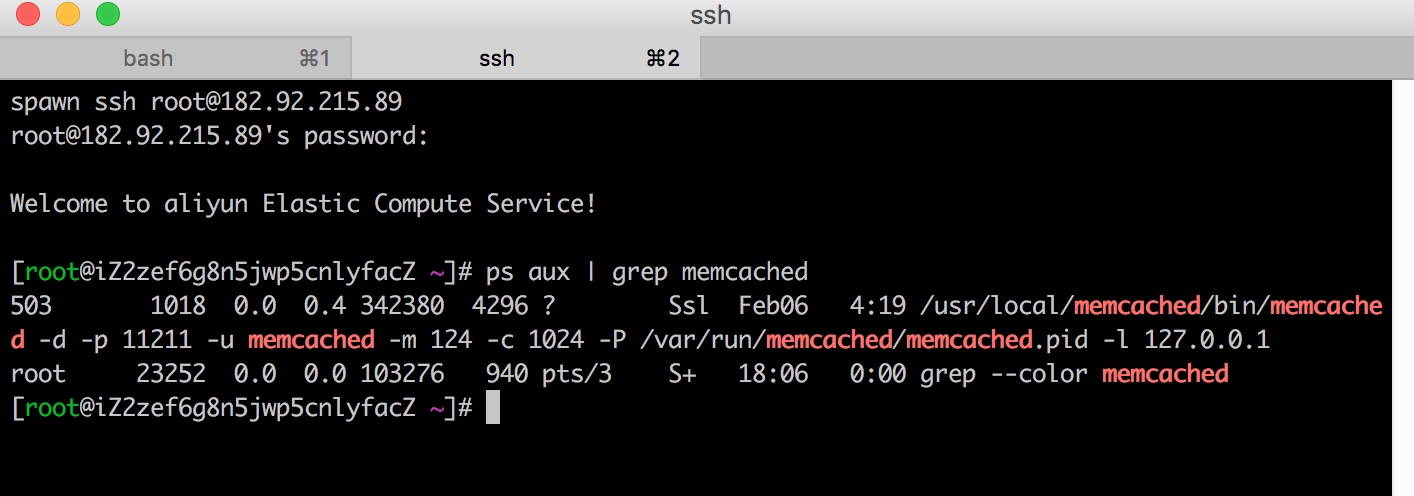
这个是我的一个阿里云服务器, 可以看到, 已经启动了memcached的守护进程. 那么来测试一下吧.
[root@iZ2zef6g8n5jwp5cnlyfacZ ~]# telnet
telnet> ^C
[root@iZ2zef6g8n5jwp5cnlyfacZ ~]#
可以看到, 安装了telnet服务, 可以使用, ok
[root@iZ2zef6g8n5jwp5cnlyfacZ ~]# telnet 127.0.0.1 11211
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
我在阿里云服务器中充当了memcache的客户端(client), 使用telnet连接memcache的服务器, 端口用ps已经看到了, 就是11211.
[root@iZ2zef6g8n5jwp5cnlyfacZ ~]# telnet 127.0.0.1 11211
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
version
VERSION 1.4.33
输入了version, 可以看到, 版本是1.4.33, ok. 一切都是正常的. 也没啥好玩的. 无非就是一些set get等操作. 不玩了.
在实际的项目当中, 肯定都是通过API来充当客户端的, 我只使用过PHP来充当客户端存储数据. 就是new一个, 然后set , get等操作. 详见php手册中, 都写的非常明白. 这里重点说一下他的运行机制和原理, 以及注意事项.
小结: 在实际项目当中, 都是给php安装memcache扩展, 然后在PHP代码中来上线memcache的存取.
memcache的运行机制
Memcached 是以守护程序方式运行于一个或多个服务器中,随时接受客户端的连接操作,客户端可以由各种语言编写,目前已知的客户端 API 包括 Perl/PHP/Python/Ruby/Java/C#/C 等等。
客户端首先与 Memcached 服务建立连接,然后存取对象。每个被存取的对象都有一个唯一的标识符 key,存取操作均通过这个 key 进行,保存的时候还可以设置有效期。
保存在 Memcached 中的对象实际上是放置在内存中的,而不是在硬盘上。Memcached 进程运行之后,会预申请一块较大的内存空间,自己进行管理,用完之后再申请一块,而不是每次需要的时候去向操作系统申请。
Memcached将对象保存在一个巨大的Hash表中,它还使用NewHash算法来管理Hash表,从而获得进一步的性能提升。所以当分配给 Memcached 的内存足够大的时候, Memcached 的时间消耗基本上只是网络Socket连接了。
Memcached 按照LRU方式调度数据。LRU是Least Recently Used的缩写,即最近最少使用页面置换算法,是为虚拟页式存储管理服务的。LRU算法在实际的工作环境中会与操作系统相关,比如32位的操作系统,最大的寻址空间是4G, 如果当前内存的使用超过了这个限度,将被调出内存,内存中总维持最新最常用的数据。64位操作系统大大扩展了内存的寻址能力,所以现在很 memcached 服务都是运行在64位系统上。
参考: http://www.cnblogs.com/leezhxing/p/3716197.html
memcache也十分的依靠客户端(client)的机制, 如:
存储过程分析 假设我们现在往memcache中存储一个缓存记录,首先在使用memcache客户端程序的时候要制定一个初始化的服务机器路由表,比如PHP的客户端程序
$mc = new Memcache();
$mc->addserver('192.168.1.110',11211);
$mc->addserver('192.168.1.120',11211);
$mc->addserver('192.168.1.130',11211);
那么在做存储的时候memcache客户端程序会hash出一个码,之后再根据路由表去将请求转发给memcache服务端,也就是说memcache的客户端程序相当于做了一个类似负载均衡的功能。
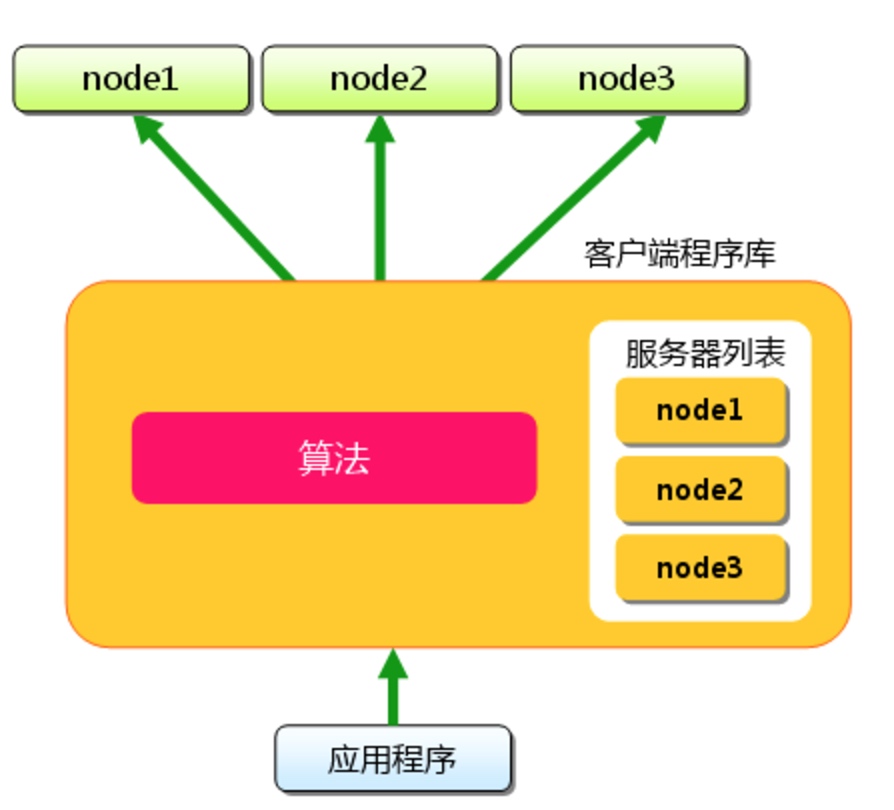
而memcache在server上面的进程仅仅负责监听服务和接受请求、存储数据的作用。分发不归他管。所以这么看的话,散列到每台memcache服务机器,让每台机器分布存储得均匀是客户端代码实现的一个难点。这个时侯Hash散列算法就显得格外重要了吧。
读取过程分析
理解了memcache的存储就不难理解memcache的读取缓存的过程了。在读取的时候也是根据key算出一个hash,之后在算出指定的路由物理机位置,再将请求分发到服务机上。
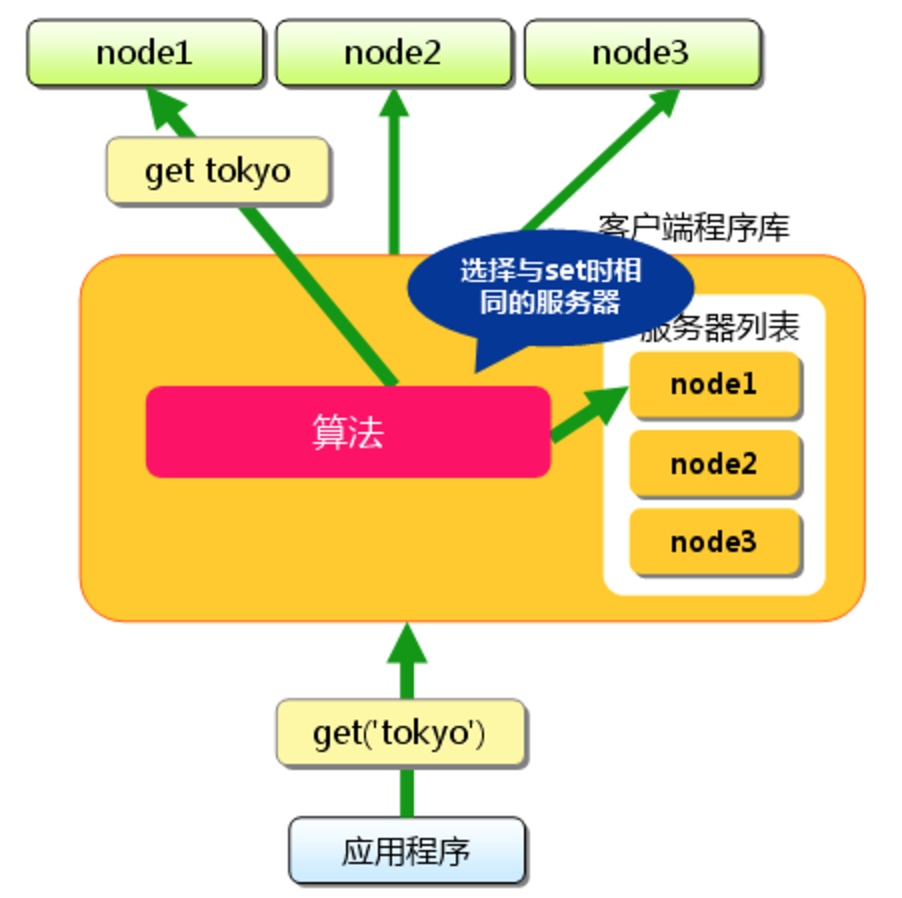
memcache分布式读写的存储方式有利有弊。如果node2宕机了,那么node2的缓存数据就没了,那么还得先从数据库load出来数据,重新根据路由表(此时只有node1和node3),重新请求到一个缓存物理机上,在写到重定向的缓存机器中。灾难恢复已经实现得较为完备。弊端就是维护这么一个高可用缓存,成本有点儿大了。为了存储更多的数据,这样做是否利大于弊,还是得看具体的应用场景再定
小结: 客户端负责服务器的分发, 服务端只存储数据.
Memcache内存分配机制
Page为内存分配的最小单位。
Memcached的内存分配以page为单位,默认情况下一个page是1M,可以通过-I参数在启动时指定。如果需要申请内存时,memcached会划分出一个新的page并分配给需要的slab区域。page一旦被分配在重启前不会被回收或者重新分配(page ressign已经从1.2.8版移除了)

Memcached pages
Slabs划分数据空间。
Memcached并不是将所有大小的数据都放在一起的,而是预先将数据空间划分为一系列slabs,每个slab只负责一定范围内的数据存储。如下图,每个slab只存储大于其上一个slab的size并小于或者等于自己最大size的数据。例如:slab 3只存储大小介于137 到 224 bytes的数据。如果一个数据大小为230byte将被分配到slab 4中。从下图可以看出,每个slab负责的空间其实是不等的,memcached默认情况下下一个slab的最大值为前一个的1.25倍,这个可以通过修改-f参数来修改增长比例。
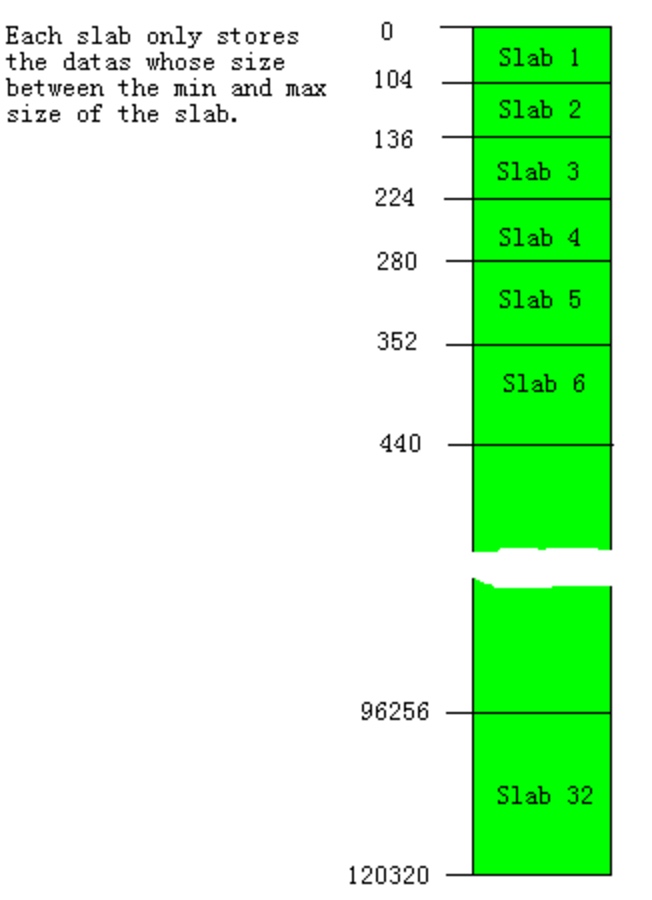
Memcached slab
Chunk才是存放缓存数据的单位。
Chunk是一系列固定的内存空间,这个大小就是管理它的slab的最大存放大小。例如:slab 1的所有chunk都是104byte,而slab 4的所有chunk都是280byte。chunk是memcached实际存放缓存数据的地方,因为chunk的大小固定为slab能够存放的最大值,所以所有分配给当前slab的数据都可以被chunk存下。如果时间的数据大小小于chunk的大小,空余的空间将会被闲置,这个是为了防止内存碎片而设计的。例如下图,chunk size是224byte,而存储的数据只有200byte,剩下的24byte将被闲置。
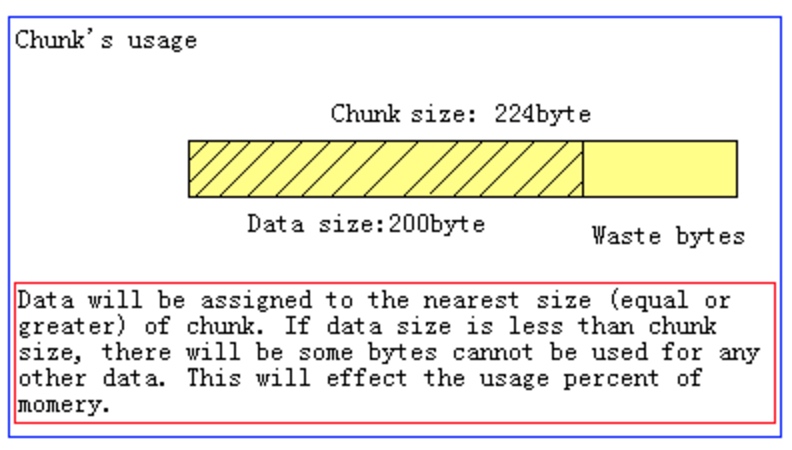
Memcached chunk
Slab的内存分配。
Memcached在启动时通过-m指定最大使用内存,但是这个不会一启动就占用,是随着需要逐步分配给各slab的。
如果一个新的缓存数据要被存放,memcached首先选择一个合适的slab,然后查看该slab是否还有空闲的chunk,如果有则直接存放进去;如果没有则要进行申请。slab申请内存时以page为单位,所以在放入第一个数据,无论大小为多少,都会有1M大小的page被分配给该slab。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk的数组,在从这个chunk数组中选择一个用于存储数据。如下图,slab 1和slab 2都分配了一个page,并按各自的大小切分成chunk数组。
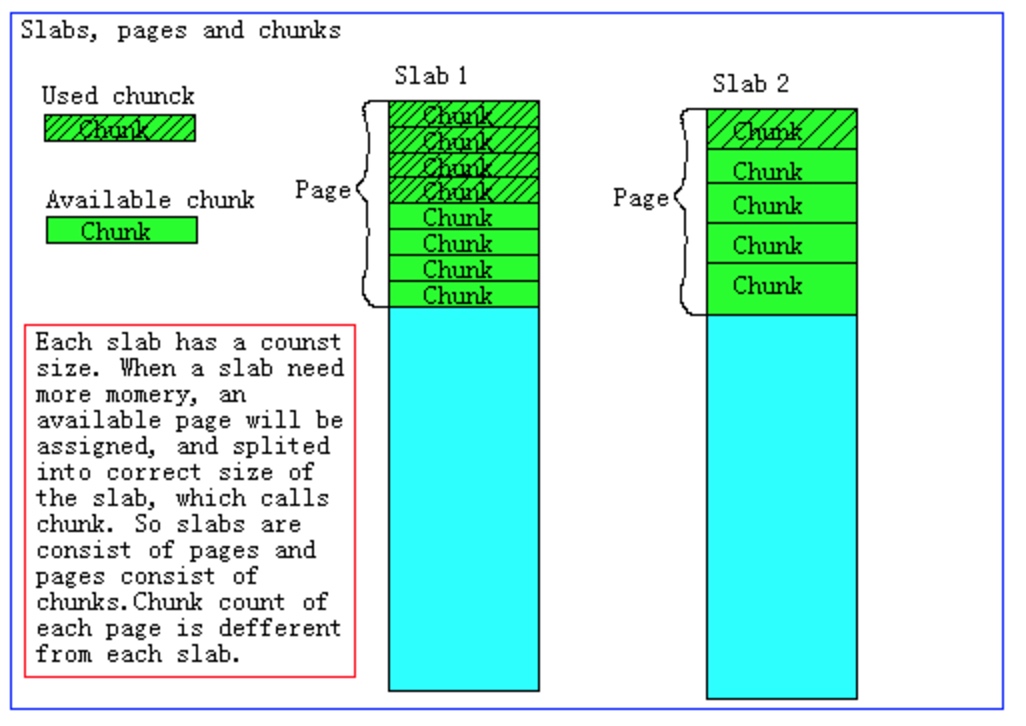
Memcached内存分配策略。 综合上面的介绍,memcached的内存分配策略就是:按slab需求分配page,各slab按需使用chunk存储。 这里有几个特点要注意,
Memcached分配出去的page不会被回收或者重新分配 Memcached申请的内存不会被释放 slab空闲的chunk不会借给任何其他slab使用
知道了这些以后,就可以理解为什么总内存没有被全部占用的情况下,memcached却出现了丢失缓存数据的问题了。
总内存没有被占用完,但是已经被分配完了,这样每个slab能够获得的内存其实已经确定了,当部分比较密集(或者开始不密集,后续增多,例如我当时遇到的,在已经基本定型的memcache上附加新的类型的应用数据,导致内存分配与数据密集程度不符)的slab出现内存不够时,会使用最久未使用算法进行移除,即使没有到达过期时间,这个时候就出现数据丢失了。但是从一些工具中,此时实际使用的内存其实没有达到最大
自问自答:

